고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
매트랩으로 코드를 짜다가 파이썬으로 넘어오면 자연스레 Numpy 눈길이 갈 것이다.
매트랩 코드를 파이썬에 맞게 수정하고 Numpy 라이브러리를 사용하면 쉽게 이식이 가능하기 때문이다.
Numpy로 만들어진 객체는 매트랩에서 사용되는 변수객체와도 유사해서 이해가 쉬웠고 그래서 이전 포스팅에서도 계속 Numpy를 이용해서 프로그램을 짰다.
[Python] numpy의 genfromtxt 함수를 이용해 csv 파일을 가져오기
저번 포스팅에서는 MATLAB에서 csv 파일을 가져오는 방법에 대해서 포스팅했었다. 같은 기능을 무료 소프트웨어인 파이썬(Python)에서 구현해보려고 한다. 컴공과도 아닌데 굳이 처음부터 개발할 이
super-master.tistory.com
하지만 Numpy 배열은 배열내의 모든 값의 자료형이 같아야 한다는 조건이 붙는다.
수학적인 계산을 하는데에는 큰 문제가 없지만 데이터 베이스를 만들기 위해서는 다양한 자료형을 담을 수 있는 일종의 엑셀표가 필요하다.
그래서 엑셀의 표와 같이 다양한 자료형을 담을 수 있는 데이터프레임(Dataframe)을 제공하는 Pandas를 사용한다.
(물론 Numpy만의 장점이 있다. 선형대수에 응용되며 무엇보다 빠르다)

엑셀과 같이 데이터를 분석한다는 용도의 관점에서 본다면 pandas가 더 포괄적으로 사용하며 이해하기도 더 쉽다.
매력적인 기능은 Pandas의 경우 text 파일, csv 파일, JSON 파일, SQL파일 등의 다양한 데이터파일을 제약없이 쉽게 가져올 수 있다.
Numpy의 경우 여러 설정이 필요했으나
import numpy as np
data = np.genfromtxt('example.csv' , skip_header = 1 , delimiter = ',' , dtype = float)Pandas의 경우는 조금더 심플하고 가져온 Data frame이 엑셀표와 유사해 이해하기도 편하다.
간단한 설정값을 설명하면
encoding = 'utf-8-sig' 은 데이터를 불러오는데 유니코드를 사용하라는 뜻이다. 가져오는 데이터가 영어가 아니라 한글 데이터 일 수도 있기 때문에 범용성과 안정성을 위해 유니코드를 사용한다.
error_bad_lines=False 는 오류가 난 부분은 제외하고 가져오라는 의미로 파일이 손상되었을때 손상된 데이터로 인해 전체 코드가 동작하지 않는 오류를 피하기 위해 사용한다.
import pandas as pd
pd.read_csv("example.csv", encoding='utf-8-sig', error_bad_lines=False)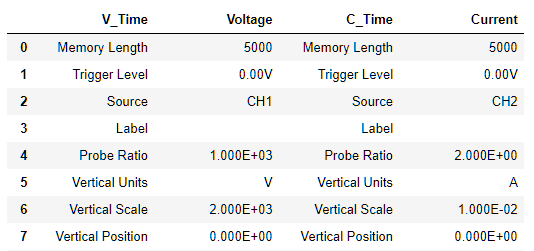
3줄 요약
1. 숫자만 쓸꺼면 Numpy를 써도 좋다
2. pandas를 사용하면 다양한 자료형을 다룰 수 있다
3. pandas는 다양한 파일형을 지원해서 데이터를 읽기도 편하고 가공하기도 편하다.
728x90
반응형
'프로그래밍 > Python' 카테고리의 다른 글
| [SciPy. Curve_Fit] 쓰기위해서 배우는 최소한의 curve_fit 함수 (0) | 2021.06.19 |
|---|---|
| [실험데이터 분석 Pandas 기초] csv데이터의 헤더에서 측정정보 추출하기 (0) | 2021.06.16 |
| [Python] 코드블록을 구간별로 나누는 방법 : #%% code block (0) | 2020.09.07 |
| [Python] 기울기가 달라지는 수치데이터 Fitting 하기 - 2 : curve_fit 함수 사용 (0) | 2020.08.30 |
| [Python] 기울기가 달라지는 수치데이터 Fitting 하기 - 1 : piecewise 함수 (0) | 2020.08.28 |




