고정 헤더 영역
상세 컨텐츠
본문
728x90

측정 데이터의 헤더는 데이터를 다룰때 귀찮은 존재지만
헤더의 존재이유를 생각하면 마냥 귀찮아 할 녀석은 아니다.
CSV file에서 HEADER란?
오실로스코프나 OES로 측정을 하고 데이터를 저장하면 실험조건 등이 header라는 이름으로 저장된다.

헤더란 일종의 표지판과 같아서 측정데이터의 경우 측정시간과 날짜, 측정조건에 대한 정보, 측정값에 대한 정보 등이 들어있다.
일회성으로 csv파일에서 값을 가져와서 계산만 한다면 사실 헤더는 의미없다.
그래서 이전의 계산프로그램에선 skip_header와 같은 명령어로 헤더정보를 빼고 파일을 불러왔다.
하지만 Python으로 자동화 코드를 짜고
이를 통해 수많은 csv 파일에서 데이터를 불러와 계산한다면 헤더파일의 정보는 데이터를 분류하는데 유용하게 사용될 수 있다.
예를 들면, 동일한 조건에서 측정한 데이터가 맞는지,
시계열로 분석한다면 이 측정데이터의 시간 순서는 어떻게 되는지 등등
헤더파일을 통해 측정조건을 알 수 있다면 측정한 데이터들을 프로그램으로 쉽게 분류가 가능하다.
실험자의 부주의로 파일순서가 엉키거나 측정조건을 잊었을때에도 (측정할 때의 장비의 Resolution과 같은 정보가 이에 해당한다) 일반적으로는 Header에 이런 조건이 저장되기 때문에 유용한 측면도 있다.
Pandas의 read_csv로 헤더정보를 가져오자
이제 측정조건이 숨어있는 헤더에서 측정조건을 추출하는 방법을 알아보자.
먼저 코드는 다음과 같다.
import pandas as pd
info = pd.read_csv("ALL0001.csv", encoding='utf-8-sig', error_bad_lines=False).reset_index()
info.columns = ["V_Time" , "Voltage", "C_Time", "Current", "None"]
del info["None"]
info.head(20)pandas 라이브러리를 pd라는 이름으로 불러오자
(다른식으로 불러도 되지만 일반적으로 pandas는 pd로 numpy는 np로 import한다)
info라는 데이터프레임에 read_csv( "파일경로", encoding = 'utf-8-sig' , error_bad_lines = False) 조건으로 csv 파일을 불러올 수 있다.
encoding = 'utf-8-sig'는 유니코드로 불러온다는 의미고
error_bad_lines = False는 오류가 있는 행은 불러오지 않는다는 의미이다. 둘다 오류 발생을 방지하기 위해 작성했다.
.reset_index() 함수는 pandas의 데이터프레임을 다루는 명령어다.
인덱스를 초기화 한다는 의미인데 원데이터가 행과 열을 잘 맞춰서 쓰여진게 아닌 경우 pandas로 불러오게 되면 다음과 같이 행과 열이 꼬여버린다. (꼬인다는 말은 인덱스와 열이 각 이름별로 잘 구성되지 않아서 분석을 하기가 어렵다는 의미이다)

.reset_index 함수를 써주면 인덱스가 첫 열에 생기고 이름이 없는 열에는 자동으로 이름이 붙는다.
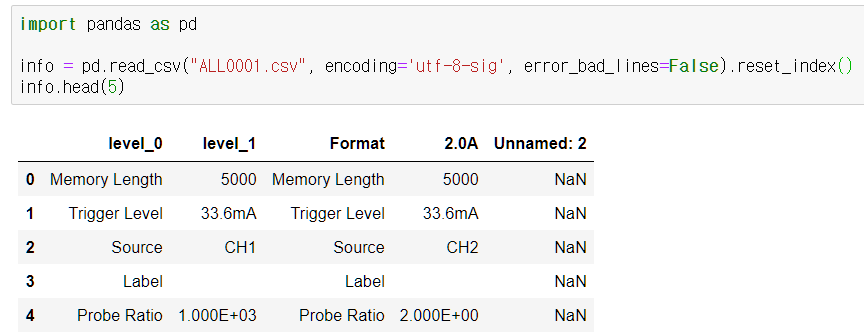
이제 데이터를 좀더 쉽게 다루기 위해 각 열(columns)에 이름을 붙여주자
V_Time 이라는 의미는 전압측정 되는 시간이라는 뜻으로 임의로 정해준 것이다.
.colums를 이용해 이름을 바꿔줄 때는 열의 숫자와 동일한 갯수로 맞춰서 만들어줘야 한다.

맨 뒤의 None으로 이름붙인 열은 아무의미 없는 열이므로 지워주도록 하자.
del info["None"] 이라고 하면 None열을 다 지워준다는 의미이다.

데이터프레임을 그래도 알아볼 수 있게 만들었으면 (인덱스랑 열이름이 다 있는 형태를 의미한다)
원하는 정보를 가져오는건 쉽다.
시간정보를 가져오려고 해보자 시간정보는 Voltage 열의 14번째 인덱스에 들어있다.

코드로 적으면 다음과 같다

Date라는 객체에 날짜 데이터를 넣어주자는 의미이다.
Pandas에는 datetime이라는 자료형이 있는데 단순한 숫자가 아니라 시간과 날짜정보로 만들어준다.
datetime으로 만들어주면 나중에 그래프를 그릴때 plotly 라이브러리가 자동으로 시계열로 인식을 해줘서 편리하다.
오실로스코프의 헤더에서 뽑아내는 정보는 측정시간, Sampling_Period, Probe_ratio 정도이다.
오실로스코프마다 설정이 달라서 바꿔야겠지만 나는 이런식으로 정리했다.
Date = pd.to_datetime(info["Voltage"][14])
Sampling_Period = float(info["Voltage"][12])
V_Probe_Ratio = float(info["Voltage"][4])
C_Probe_Ratio = float(info["Current"][4])3줄요약
1. csv의 헤더에는 실험장비의 측정조건와 같은 정보들이 들어있다.
2. pandas로 csv파일을 불러올 때 데이터전처리를 통해 데이터프레임을 사용하기 쉽게 가공하는 작업이 필요하다.
3. 데이터프레임을 먼저 만든 다음, 데이터프레임에서 열의 이름과 인덱스 번호를 통해 원하는 정보를 추출할 수 있다.
728x90
'프로그래밍 > Python' 카테고리의 다른 글
| [SciPy. curve_fit] curve_fit을 조금더 이해해보자 (0) | 2021.06.19 |
|---|---|
| [SciPy. Curve_Fit] 쓰기위해서 배우는 최소한의 curve_fit 함수 (0) | 2021.06.19 |
| [파이썬 데이터분석공부] Pandas와 Numpy 무엇을 써야할까? (0) | 2021.06.15 |
| [Python] 코드블록을 구간별로 나누는 방법 : #%% code block (0) | 2020.09.07 |
| [Python] 기울기가 달라지는 수치데이터 Fitting 하기 - 2 : curve_fit 함수 사용 (0) | 2020.08.30 |




